Ein Projekt von Tarek Sabet.
Der Chaos Communication Congress ist ein jährlicher Hackerkongress mit derzeit ca. 15 000 Besuchern. Auf dem Kongress Ende 2017 (34C3) betreute ich eine Assembly zu Maschinellem Lernen. Dies bedeutet, dass ich einen Stand aufbaute und dort Interessierten im direkten Gespräch Fragen beantwortete, um ihnen so einen groben Uberblick über Machine Learning zu geben.
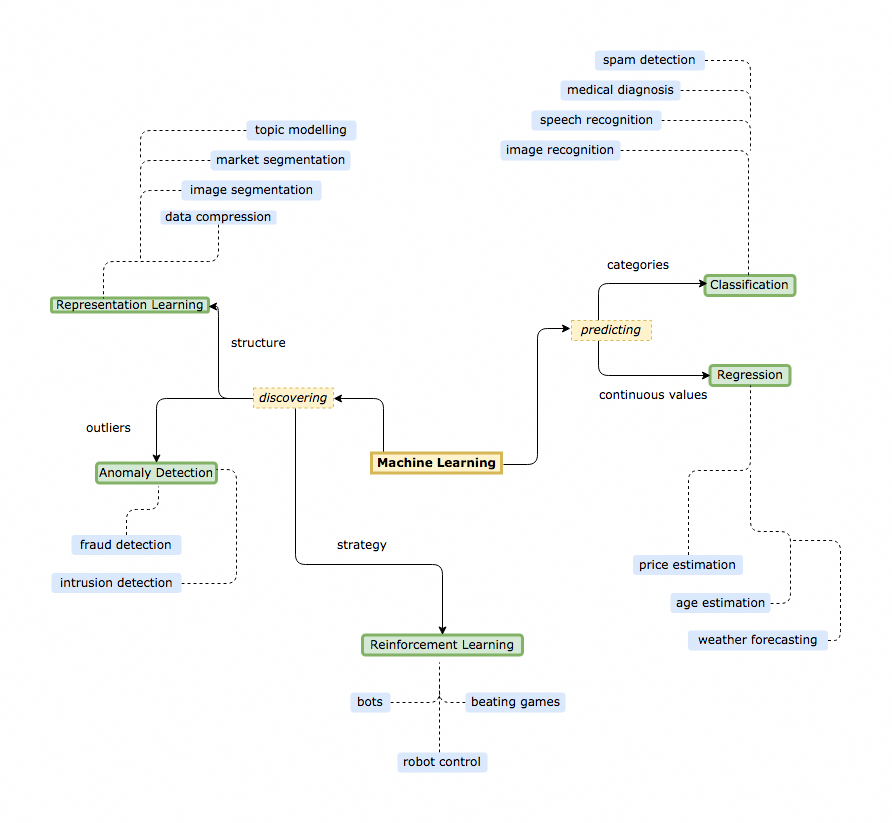
Maschinelles Lernen ist eine Disziplin, die sich damit befasst wie Computer sich selbst Fähigkeiten aneignen können, ohne dass sie diese explizit einprogrammiert bekommen. Hierzu zählen Fähigkeiten wie z.B. Bilderkennung, Spracherkennung, oder ein Auto zu fahren. Maschinelles Lernen ist in den letzten Jahren sehr erfolgreich, die Technologie begegnet uns schon heute bei alltäglichen Google-Suchen oder Spotify-Musikempfehlungen.
Obwohl der Congress hauptsächlich von technisch und wissenschaftlich interessierten Menschen besucht wird, merkte ich im Gespräch immer wieder, dass sich im Bereich des Maschinellen Lernens bisher nur Wenige auskennen. Da ich denke, dass diese Technologie großen gesellschaftlichen Einfluss haben wird, war es mir wichtig, Interesse dafür zu wecken.
Maschinelles Lernen ist in erster Linie ein Teilgebiet der Statistik. Systeme, die Maschinelles Lernen benutzen, müssen lernen, unter Ungewissheit sinnvoll zu agieren. Zum Beispiel muss eine Gesichtserkennungssoftware entscheiden, wie wahrscheinlich es ist dass ein bestimmtes Gesicht im Bild ist, gegeben den Farben, die die Pixel des Bildes haben. Für unterschiedliche Probleme gibt es unterschiedliche stochastische Modelle die sich bewährt haben. So ist es – um bei dem Beispiel Bilderkennung zu bleiben – nützlich, wenn ein Modell so konstruiert ist, dass es ein sogenanntes “Vorurteil” hat, dass benachbarte Bildpunkte etwas miteinander zu tun haben.
Anschaulich und vereinfacht würde die Maschine sonst jedes Produkt in einem großen Regal im Supermarkt scannen. Der Mensch aber sieht drei Sorten Spaghetti und eine Reihe Penne und hört auf, nach der Cola zu suchen. Diese Fähigkeit versucht man auch Computern beizubringen. Ein sehr erfolgreiches Modell dieser Art nennt sich Convolutional Neural Network, dessen Benutzung und Funktionsweise ich am Computer demonstriert habe.

Da wir heutzutage immer mehr Informationen ausgesetzt sind, sprach ich über Topic Modelling und Recommender Systems. Beim Topic Modelling befasst man sich damit viele Dokumente – wie etwa E-Mails – in unterschiedliche Themen zu unterteilen, um sie leichter durchsuchbar zu machen. Recommender Systems geben Empfehlungen für Produkte oder Artikel, die einer gewissen Zielgruppe gefallen, auf Grundlage anderer Bewertungen, die diese abgegeben haben. Diese Maschinenintelligenz arbeitet zum Beispiel im Hintergrund, wenn Youtube ein Video empfiehlt.
Machine Learning Modelle können aber auch zu gewissem Grad selbst gebaut werden, sofern man ausreichend Daten und Rechenleistung hat. Das versuche ich mit einer Machine Learing Arbeitsgruppe regelmäßig und konnte so Fragen über technische Details, etwa zur Rechenleistung, beantworten. Oft wurde ich auch gefragt, für welches Problem welches Modell am vielversprechendsden ist. Hierbei ist es natürlich schwierig, in einem gerade entstehenden und wachsenden Feld einen vollständigen Überblick vermitteln zu wollen, aber ich war froh, wenn ich grobe Richtungen empfehlen konnte: Für Daten die eine zeitliche Komponente haben sind Recurrent Neural Networks in der Regel eine gute Wahl, fur Bildgeneration können Generative Adversarial Networks oder Variational Autoencoders gute Ergebnisse liefern.
Wichtig war mir aber auch, uber die Gesellschaftlichen Folgen des Maschinellen Lernens zu sprechen. In den Gesprächen kamen folgende Themen auf: Die Automation, die durch diese Technologie ermöglicht wird, wird vermutlich einen Großteil der Arbeitsplätze redundant machen. Wir stecken vielleicht in einem Umbruch, der mit der Industrialisierung vergleichbar ist. Auf die Folgen dieser Entwicklung, muss wohl die Politik reagieren.
Eine zweite Uberlegung richtet sich an unsere Gerichte: Es existieren Methoden, um realgetreue Stimmen und Videos mit dem Computer zu generieren, was starke Implikationen fur die Zulässigkeit von gerichtlichen Beweismitteln hat, ganz zu schweigen von dem Schaden der durch einfach herzustellenden realistischen Fälschungen ausgehen kann.
Militärische Anwendungen von Maschinellem Lernen sind selbstverständlich inzwischen auch im Einsatz, was ethische Fragestellungen aufwirft, wie etwa die automatische Zielerfassung durch Drohnen.
Vor allem angesichts dieser gesellschaftlich relevanten Auswirkungen der Technologie finde ich es wichtig, dass
die Menschen sich daruber informieren können, was heutzutage möglich ist und was bald möglich sein wird, um
meiner Meinung nach notwendige Debatten zu führen.